I suspect the cause of all the issues is due to pre-calculating all the triangles and rectangles for the ships, buildings, trees and particles.
There's an array of ships which contains their details and a pointer to the code to control them. They are then added to a 2D array (64x64 I think), containing a list of objects in each map pixel. Before plotting the landscape the array is scanned for visible objects, these are then translated to a 2D triangle list and added to another 2D array containing a plot list for every visible landscape block. It then does the same for particles, which are stored in the plot table as a position and type (there's 16 types), which define the size and colour.
When the landscape is plotted, it plots a full row of landscape tiles followed by a full row of pre-calculated triangles/particles from two rows back, this is an approximation of Z sorting everything.
So there's arrays of arrays and a lot of wasted cycles accessing them where it pre-calculates the triangle/particle plot list. What I intend to do is merge all the plot code together, so it's calculated JIT and plotted directly to screen. This should substantially reduce the memory footprint (the plot table is 128Kb IIRC) and hopefully give a measurable speed boost. I'll probably do this on a row basis to reduce stack use.
I forgot to mention that I did spend a few days on the BASIC quadrilateral code, which is now better behaved. There's still a few overruns, which are causing negative length lines to be passed to the line fill code, I'll probably have to live with these and add trap code for them. It's at a stage where I can now look at register assignment and possibly attempt to recode it into assembler.
I've not looked in detail at the new triangle routine, I have coded a BASIC version of it, but I'm not happy with it as its not as accurate as the quad routine and needs to sort the coordinates. The quad routine avoids sorting because it knows the order the four coordinates are in and deals with them in based on their probability (ie quads that are more common are handled first.)
Although the ARM2 optimised line fill is done, I may have to modify it due to a shortage of registers. It currently requires four colour registers, these are setup for every line fill, which is very wasteful for short lines. This is exacerbated with the increased plot depth, where the bulk of lines are <6 pixels. I've not redone the statistical analysis yet, but have worked out that the cutover between a string of STRB's and the new routine is 8 pixels (4000nS) - the setup of colour registers and jump to the optimised code takes 2500nS.
My current thought is to move the setup of colour registers into the optimised line fills themselves. For example, it will only preserve and setup four colour registers if it's going to do an STM with four registers, this will give a speed improvement to the bulk of line fills at the expense of possibly pushing the max line fill code length over the current 64 byte limit. The end result being the line fill code table may have to double in size.
Which leads me neatly onto memory requirements. It's currently sitting around 800Kb, due to the increased Zarch table sizes, the reciprocal table, optimized line fill and palette translation table. Getting it to run on a 1mb machine is going to be tight.
Hacker needed ... for Zarch ;-)
Re: Hacker needed ... for Zarch ;-)
Below is the BASIC code for the Quad routine I'm proposing to recode into assembler. It currently requires 20 registers if the screen dimensions are fixed, 22 if not, so I need to work out the optimal way to preserve/restore registers.
Based on the possibility I may have to fall back to one colour register, I've done a cost comparison of 1 vs 4 fixed colour registers on the optimized line fill code:
With only 1 colour register the cost of a line fill is on average 22% higher between the bulk of Quad line fill lengths (13-27). Compared to the original Zarch routine however these are substantially quicker, 190% (4 colour registers) and 155% (1 colour register) respectively:
EDIT: The Quad routine is more convoluted than a Quad routine ordinarily needs to be, the reason is simply efficiency. By avoiding a Y coordinate sort on entry it saves around 1500nS, the different type of quads are then dealt with in order of their likelihood and the % of quads that match each particular type are detailed in the code.
To speed up vector calculations, it uses a 128x128 vector lookup table which is the only bit I've currently coded into assembler.
There's two precision variables, PRECISION% and EXTRA_PRECISION% which improve the accuracy of the quads. The former will increase the X by 1/2 the vector value and the later will calculate in half pixels. I don't think they're going to add much to the overall time, but do improve the look of the quads.
EDIT2: I've updated the graphs so the scales match and have included the setup cost to jump to the correct line fill code, from entry to the line fill routine.
EDIT3: To make the code more legible and closer to its assembler equivalent, I've moved the vector calculations into functions.
Based on the possibility I may have to fall back to one colour register, I've done a cost comparison of 1 vs 4 fixed colour registers on the optimized line fill code:
- 4 colour registers. X axis: Line length, Y axis: cost in nS, Z axis: Byte alignment within Quad word
- 1 colour register. X axis: Line length, Y axis: cost in nS, Z axis: Byte alignment within Quad word
- Zarch original. X axis: Line length, Y axis: cost in nS, Z axis: Byte alignment within Quad word
Code: Select all
PCR_log2%=8 : REM Fixed point float for precalc_recip table
SH%=19 : REM precision shift
ymax=8 : REM Max reciprical (Log2)
PRECISION%=TRUE : REM Increase precision of coordinates
EXTRA_PRECISION%=TRUE : REM Extra precision in Quadrilaterals
SCREEN_BOTTOM%=256
SCREEN_WIDTH%=320
precalc_recip%=1 << (PCR_log2%-1)
DIM code% 128*1024
PROCass
CALL calc_recip_table
END
DEF PROCquad(BRx%,BRy%,TRx%,TRy%,BLx%,BLy%,TLx%,TLy%,COL%)
LOCAL L%
REM remove back faces
IF TLy%>BLy% OR TRy%>BRy% THEN ENDPROC
IF TRy%>=TLy% THEN
REM 80.37% overall
IF TRy%<=BLy% THEN
REM 99.02% (79.58% overall)
IF TRy%>SCREEN_BOTTOM% AND TLy%>SCREEN_BOTTOM% THEN
REM 52.69% (38.13% overall)
ENDPROC
ENDIF
Q%=SCREEN_ADDRESS% + (TLy%*SCREEN_WIDTH%)
XS1%=FNquick_vector1(BLy%,TLy%,BLx%,TLx%)
L%=TRy%-TLy%
XS2%=FNquick_vector2(L%,TRx%,TLx%)
XP1%=TLx% << SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
XP2%=XP1% + (XS2%>>1)
IF TRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TRy%
ENDIF
Z%=FNplot_vector(3)
L%=BRy%-TRy%
XS2%=FNquick_vector2(L%,BRx%,TRx%)
IF BLy%<=BRy% THEN
REM 45.63% (39.89% overall)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TRy%
ELSE
L%=BLy%-TRy%
ENDIF
ELSE
REM 1.68% (1.55% overall)
IF BRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TRy%
ENDIF
ENDIF
IF PRECISION% THEN XP2%=(TRx% << SH%) + (XS2%>>1)
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
Z%=FNplot_vector(4)
L%=BLy%-BRy%
IF L%=0 THEN
REM 26.44% (22.99% overall)
ENDPROC
ENDIF
IF L%<0 THEN
REM 19.18% (16.90% overall)
IF BLy%>SCREEN_BOTTOM% THEN ENDPROC
L%=-L%
XS1%=FNquick_vector2(L%,BRx%,BLx%)
IF PRECISION% THEN XP1%=BLx% << SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
IF BRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BLy%
ENDIF
ELSE
REM 1.68% (1.55% overall)
IF BRy%>SCREEN_BOTTOM% THEN ENDPROC
XS2%=FNquick_vector2(L%,BLx%,BRx%)
IF PRECISION% THEN XP2%=BRx% << SH%
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BRy%
ENDIF
ENDIF
Z%=FNplot_vector(5)
ELSE
REM (0.79% overall)
IF BRy%>SCREEN_BOTTOM% THEN ENDPROC
Q%=SCREEN_ADDRESS% + (TLy%*SCREEN_WIDTH%)
XS2%=FNquick_vector1(TRy%,TLy%,TRx%,TLx%)
L%=BLy% - TLy%
XS1%=FNquick_vector2(L%,BLx%,TLx%)
XP1%=TLx% << SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
XP2%=XP1% + (XS2%>>1)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TLy%
ENDIF
Z%=FNplot_vector(6)
IF TRy%>=BLy% THEN
L%=TRy%-BLy%
XS1%=FNquick_vector1(BRy%,BLy%,BRx%,BLx%)
IF PRECISION% THEN XP1%=BLx% << SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
IF TRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BLy%
ENDIF
Z%=FNplot_vector(7)
L%=BRy%-TRy%
IF L%>0 THEN
REM 43.03% (0.38% overall)
XS2%=FNquick_vector2(L%,BRx%,TRx%)
IF PRECISION% THEN XP2%=TRx% << SH%
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BRy%
ENDIF
Z%=FNplot_vector(8)
ENDIF
ENDIF
ENDIF
ELSE
REM 16.58% overall
IF TRy%>SCREEN_BOTTOM% THEN
REM 9.7%
ENDPROC
ENDIF
Q%=SCREEN_ADDRESS% + (TRy%*SCREEN_WIDTH%)
IF BRy%<TLy% AND TRy%<BLy% THEN
XS1%=FNquick_vector1(TLy%,TRy%,TLx%,TRx%)
L%=BRy%-TRy%
XS2%=FNquick_vector2(L%,BRx%,TRx%)
XP1%=TRx% << SH%
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
XP2%=XP1% - (XS1%>>1)
IF TRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TRy%
ENDIF
Z%=FNplot_vector(9)
IF PRECISION% THEN XP2%=BRx%<<SH%
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
XS2%=FNquick_vector1(BLy%,BRy%,BLx%,BRx%)
IF TLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TLy%
ELSE
L%=TLy%-BRy%
ENDIF
Z%=FNplot_vector(10)
IF PRECISION% THEN XP1%=TLx%<<SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
XS1%=FNquick_vector1(BLy%,TLy%,BLx%,TLx%)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BLy%
ELSE
L%=BLy%-TLy%
ENDIF
Z%=FNplot_vector(11)
ELSE
XS2%=FNquick_vector1(BRy%,TRy%,BRx%,TRx%)
L%=TLy%-TRy%
XS1%=FNquick_vector2(L%,TLx%,TRx%)
XP2%=TRx% << SH%
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
XP1%=XP2% + (XS1%>>1)
IF TLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TRy%
ENDIF
Z%=FNplot_vector(0)
IF PRECISION% THEN XP1%=TLx%<<SH%
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
XS1%=FNquick_vector1(BLy%,TLy%,BLx%,TLx%)
IF BLy%>=BRy% THEN
REM 41.42% (8.13% overall)
IF BRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TLy%
ELSE
L%=BRy%-TLy%
ENDIF
ELSE
REM 0.22% (0.04% overall)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-TLy%
ELSE
L%=BLy%-TLy%
ENDIF
ENDIF
Z%=FNplot_vector(1)
L%=BLy%-BRy%
IF L%>=0 THEN
REM 41.42% (8.13% overall)
XS2%=FNquick_vector2(L%,BLx%,BRx%)
IF PRECISION% THEN XP2%=(BRx% << SH%) - (XS2%>>1)
IF EXTRA_PRECISION% THEN XP2%+=1<<(SH%-1)
IF BLy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BRy%
ENDIF
ELSE
REM 0.22% (0.04% overall)
L%=-L%
XS1%=FNquick_vector2(L%,BRx%,BLx%)
IF PRECISION% THEN XP1%=(BLx% << SH%) + (XS1%>>1)
IF EXTRA_PRECISION% THEN XP1%+=1<<(SH%-1)
IF BRy%>SCREEN_BOTTOM% THEN
REM clip bottom of screen
L%=SCREEN_BOTTOM%-BLy%
ENDIF
ENDIF
ENDIF
Z%=FNplot_vector(2)
ENDIF
ENDPROC
DEF FNquick_vector1(Ay%, By%, Ax%, Bx%)
tmp%=(Ay%-By%)<<PCR_log2%
tmp%+=Ax%
tmp%-=Bx%
=quick_vector!(tmp%<<2)
DEF FNquick_vector2(A%, Ax%, Bx%)
tmp%=A%<<PCR_log2%
tmp%+=Ax%
tmp%-=Bx%
=quick_vector!(tmp%<<2)
DEF FNplot_vector(STAT_entry%)
WHILE L%>0
PROCline(XP1%, XP2%)
XP1%+=XS1%
XP2%+=XS2%
Q%+=SCREEN_WIDTH%
L%-=1
ENDWHILE
=0
DEF PROCline(L%,R%)
L%=L%>>SH%
R%=R%>>SH%
IF L%>=SCREEN_WIDTH% OR R%<0 OR L%>R% THEN ENDPROC
IF L%<0 THEN L%=0
IF R%>=SCREEN_WIDTH% THEN R%=SCREEN_WIDTH%-1
REM plot the pixels
FOR Z%=L% TO R%:Q%?Z%=COL%:NEXT
ENDPROC
DEF PROCass
ysize=1<<ymax
FOR A%=0 TO 2 STEP 2
P%=code%
[OPT A%
.calc_recip_table
STMFD R13!, {R0-R12, R14}
MOV R0, #0
MOV R1, #ysize-1
ADR R12, recip
STR R0, [R12, #0]
._calc_recip_table_L1
MOV R7, #0
MOV R10, #1 << (SH% + 3)
MOV R9, R1, LSL #31 - ymax
MOV R14, #1 << SH%
._calc_recip_table_L2 ;R7=R10/R9
MOVS R14, R14, LSL #1
CMPCC R14, R9
SUBCS R14, R14, R9
ORRCS R7, R7, R10
MOVS R10, R10, LSR #1
BCC _calc_recip_table_L2
STR R7, [R12, R1, LSL #2]
SUBS R1, R1, #1
BNE _calc_recip_table_L1
.calc_quick_vector_table
ADR R11, quick_vector
MOV R0, #0
._calc_quick_vector_table_LY
MVN R1, #precalc_recip% - 1
LDR R2, [R12, R0, LSL #2] ;get Y reciprocal
._calc_quick_vector_table_LX
MUL R3, R2, R1 ;=recip / Y
STR R3, [R11, R1, LSL #2]
ADD R1, R1, #1
TEQ R1, #precalc_recip%
BNE _calc_quick_vector_table_LX
ADD R11, R11, #precalc_recip% << 3
ADD R0, R0, #1
TEQ R0, #precalc_recip%
BNE _calc_quick_vector_table_LY
LDMFD R13!, {R0-R12, PC}
.recip
]:P%+=ysize<<2:[OPT A% : REM 1Kb
.quick_vector
]:P%+=((precalc_recip% << 3) * precalc_recip%) << 2 : REM 64Kb
NEXT
ENDPROCTo speed up vector calculations, it uses a 128x128 vector lookup table which is the only bit I've currently coded into assembler.
There's two precision variables, PRECISION% and EXTRA_PRECISION% which improve the accuracy of the quads. The former will increase the X by 1/2 the vector value and the later will calculate in half pixels. I don't think they're going to add much to the overall time, but do improve the look of the quads.
EDIT2: I've updated the graphs so the scales match and have included the setup cost to jump to the correct line fill code, from entry to the line fill routine.
EDIT3: To make the code more legible and closer to its assembler equivalent, I've moved the vector calculations into functions.
Last edited by sirbod on Thu Feb 16, 2023 8:07 am, edited 1 time in total.
Re: Hacker needed ... for Zarch ;-)
I'll be creating the diff package based on the version of Zarch on Qube Server, so suggest anyone interested in this project grab a copy.
Last edited by sirbod on Fri Apr 28, 2017 10:33 pm, edited 1 time in total.
Re: Hacker needed ... for Zarch ;-)
Itching for an update 
Re: Hacker needed ... for Zarch ;-)
I refer the honourable gentleman to my post on 10th Jan, which contains the Quad routine and speed graphs of the optimized line fill. Before proceeding, I was awaiting some peer review.trixster wrote:Itching for an update
When I started juggling register allocations it became clear that at minimum 6 need to be stacked, the obvious ones are the input values (x1, y1 .. x4, y4) as they're only used to set the start position and calculate the vectors. Annoyingly Zarch already stores/loads them before calling the quad routine and to make matters worse the quad routine needs at least 8000nS just for the entry/exit as it needs to preserve R9-R12 and stack R0-R7 due to the lack of registers.
Register assignment I settled on for the quad/line routines:
Code: Select all
quad (R0-R7, R9-R12, R14 need to be stacked on entry)
----
input:
R0 x1 / BRx%
R1 y1 / BRy%
R2 x2 / TRx%
R3 y2 / TRy%
R4 x3 / BLx%
R5 y3 / BLy%
R6 x4 / TLx%
R7 y4 / TLy%
R8 COL%
run values:
R0 tmp1 (temporary register)
R1 Q% (start address of current Y)
R2 XS1%
R3 XS2%
R4 XP1%
R5 XP2%
R6 L%
R7 col1
R8 col2 (COL%)
R9 col3
R10 col4
R11 tmp2 (temporary register)
R12 quick_vector / SCREEN_BOTTOM% (if not fixed) / SCREEN_WIDTH% (if not fixed)
R14 SCREEN_ADDRESS% (only used once on Q% setup) / tmp3 (temporary register)
exit:
R0-R8 corrupt
R9-R12 preserved
line
----
input values:
R4 L% (XP1%)
R5 R% (XP2%)
R7 col1
R8 col2
R9 col3
R10 col4
run values:
R0 count = (XP2%-XP1%)>>SH%
R11 addr1 = Q% + (XP1%>>SH%)
R12 SCREEN_WIDTH% (if not fixed)
exit:
R0, R11, R12 corruptRe: Hacker needed ... for Zarch ;-)
I've posted a video on YouTube discussing the issues, investigation undertaken to date and demonstrating what it looks like on a Pi.
Last edited by sirbod on Fri Apr 28, 2017 11:58 pm, edited 3 times in total.
Re: Hacker needed ... for Zarch ;-)
Here it is for the rest of us.sirbod wrote:I've posted a video on YouTube discussing the issues, investigation undertaken to date and demonstrating what it looks like on a Pi.
Re: Hacker needed ... for Zarch ;-)
Just watched it, what a great video!
-
Rich Talbot-Watkins

- Posts: 2054
- Joined: Thu Jan 13, 2005 5:20 pm
- Location: Palma, Mallorca
- Contact:
Re: Hacker needed ... for Zarch ;-)
Great work so far!
My comment on the colours is that I think the alternative palette would probably still look better, even despite the lack of full white. There are some nice gradations from green and blue to black in that palette, although no pure greys at all - perhaps that's a deal-breaker. I don't know if you're doing it already (or considering it), but dithered colours would also be a good way to expand your perceived palette (with a ROR#8 on the colour register between each line). Are you still using ColourTrans, or are you building tables yourself now? Remember, gamma correction can also help you to get a smoother fade to black (I don't believe ColourTrans does that).
Really amazing to see it running like that, and it's very interesting to see your runtime analysis of poly sizes and so on!
My comment on the colours is that I think the alternative palette would probably still look better, even despite the lack of full white. There are some nice gradations from green and blue to black in that palette, although no pure greys at all - perhaps that's a deal-breaker. I don't know if you're doing it already (or considering it), but dithered colours would also be a good way to expand your perceived palette (with a ROR#8 on the colour register between each line). Are you still using ColourTrans, or are you building tables yourself now? Remember, gamma correction can also help you to get a smoother fade to black (I don't believe ColourTrans does that).
Really amazing to see it running like that, and it's very interesting to see your runtime analysis of poly sizes and so on!
Re: Hacker needed ... for Zarch ;-)
It doesn't currently dither colours, but it is something I've considered adding when I drop the new line fill routine in. The demo already uses an RGB lookup table, so it's simply a case of increasing the table size to lookup a word instead of a byte and ROR based on the screen Y.Rich Talbot-Watkins wrote:I don't know if you're doing it already (or considering it), but dithered colours would also be a good way to expand your perceived palette (with a ROR#8 on the colour register between each line). Are you still using ColourTrans, or are you building tables yourself now? Remember, gamma correction can also help you to get a smoother fade to black (I don't believe ColourTrans does that).
I used ColourTrans to build the initial RGB lookup table, Steve also had a go with his own routines but its still limited by the VIDC palette restrictions. Dithering is probably the best solution on VIDC, with 24bit on GPU based machines.
Re: Hacker needed ... for Zarch ;-)
Does anyone have some code to select the optimal two palette entries to use for a 50% ordered dither in MODE 13? I'm redefining the VIDC palette, so need to pick two entries from a 256 entry table that combined, provide the lowest delta from the required colour, but not too far from each other that its visually displeasing.
Re: Hacker needed ... for Zarch ;-)
I believe Steve3000 worked that out for his part in the Quantum Liquid dreams demo ...sirbod wrote:Does anyone have some code to select the optimal two palette entries to use for a 50% ordered dither in MODE 13? I'm redefining the VIDC palette, so need to pick two entries from a 256 entry table that combined, provide the lowest delta from the required colour, but not too far from each other that its visually displeasing.
https://youtu.be/Md95AfTGuaQ?t=1m32s
-
Rich Talbot-Watkins
- Posts: 2054
- Joined: Thu Jan 13, 2005 5:20 pm
- Location: Palma, Mallorca
- Contact:
Re: Hacker needed ... for Zarch ;-)
I'm assuming this applies to the Archimedes, and that it doesn't have a non-linear colour scale or anything tricky like that. On the PC, at least, I would be matching colours in gamma-corrected colourspace, as that's what you're essentially 'seeing'.
In order to match a 50% grey, the best match here is a grey of (186, 186, 186) - this comes from 0.5^(1/2.2) * 255.
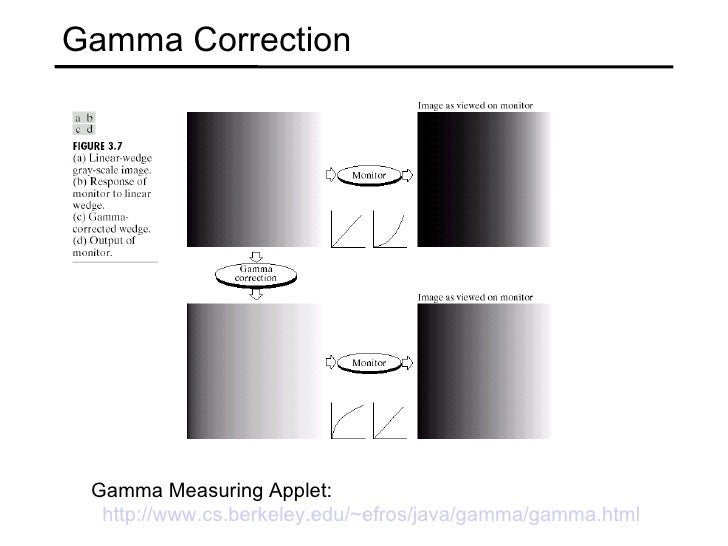
So, transform your target colour to gamma-corrected space by normalising and raising to the power (1/2.2). Then you need to find the palette entry with the nearest Euclidean distance to your gamma-corrected target, weighting RGB by (0.3, 0.6, 0.1).
To find dithered pairs is a bit different. The 'effective' colour of a dithered pair is the gamma-corrected average. So dithering (0, 0, 0) with (255, 255, 255) yields a colour which is closest visually to (186, 186, 186), even though the average is (128 128, 128). So when searching dithered pairs, do so in the original colour space.
Good article here on gamma: http://blog.johnnovak.net/2016/09/21/wh ... out-gamma/
Edit: something doesn't check out with what I wrote above about dithering, I'll need to think about it a bit more. I always have to relearn gamma correction from first principles every time I have to deal with it.
In order to match a 50% grey, the best match here is a grey of (186, 186, 186) - this comes from 0.5^(1/2.2) * 255.
So, transform your target colour to gamma-corrected space by normalising and raising to the power (1/2.2). Then you need to find the palette entry with the nearest Euclidean distance to your gamma-corrected target, weighting RGB by (0.3, 0.6, 0.1).
To find dithered pairs is a bit different. The 'effective' colour of a dithered pair is the gamma-corrected average. So dithering (0, 0, 0) with (255, 255, 255) yields a colour which is closest visually to (186, 186, 186), even though the average is (128 128, 128). So when searching dithered pairs, do so in the original colour space.
Good article here on gamma: http://blog.johnnovak.net/2016/09/21/wh ... out-gamma/
Edit: something doesn't check out with what I wrote above about dithering, I'll need to think about it a bit more. I always have to relearn gamma correction from first principles every time I have to deal with it.
Re: Hacker needed ... for Zarch ;-)
There's no requirement to do gamma correction. Calculate the distance of all palette entries from the required RGB: D=(R1-R2)^2 + (G1-G2)^2 + (B1-B2)^2 and then find the pair with the lowest distance from both each other and the required colour when combined.
I was hoping someone had already coded something similar, to save me a few hours.
I was hoping someone had already coded something similar, to save me a few hours.
-
Rich Talbot-Watkins
- Posts: 2054
- Joined: Thu Jan 13, 2005 5:20 pm
- Location: Palma, Mallorca
- Contact:
Re: Hacker needed ... for Zarch ;-)
There's no requirement, but clearly it makes blends look smoother if it's applied (e.g. interpolation towards black). Since a visually 50% grey actually corresponds to 73% grey on the linear scale, if you don't perform gamma correction, you'll find your scene going to black too suddenly. One of the reasons jsbeeb's MODE 7 glyphs look right is because the anti-aliasing is gamma corrected.
It's sometimes claimed the Euclidean distance calculation should weight the RGB elements by the amounts according to human perception, so something more like:
Last time I had to do a nearest colour check, I ended up converting to YUV and comparing distances in that colour space, as it gave far better results, but that's a lot more involved!
It's sometimes claimed the Euclidean distance calculation should weight the RGB elements by the amounts according to human perception, so something more like:
Code: Select all
D=sqrt(0.3*dr*dr + 0.6*dg*dg + 0.1*db*db)Re: Hacker needed ... for Zarch ;-)
I've knocked up a dither test, which looks truly awful. It currently doesn't rotate the dither based on Y as the line fill doesn't know what it is - I'll need to modify the triangle routine to resolve that. When calculating the dither table, I'm not checking the distance between the two chosen colours, so the dither is very noticeable. On the positive side, it does fade to black a lot better.


- With dithering
- zarch_extra_3_front_default_palette_dither_test.png (24.76 KiB) Viewed 15849 times
- Without dithering
- zarch_extra_3_front_default_palette_no_dither.png (13.92 KiB) Viewed 15849 times
Re: Hacker needed ... for Zarch ;-)
I've modified the dither colour calculation to prefer two colours that are close to each other, foreground dithering is now barely noticeable:
 EDIT: Updated the image with the latest iteration. I've now updated Zarch's original triangle, quadrilateral and short line fill length routines to account for the X,Y position of the fill within the 50% dither.
EDIT: Updated the image with the latest iteration. I've now updated Zarch's original triangle, quadrilateral and short line fill length routines to account for the X,Y position of the fill within the 50% dither.
- Dithered using colours with low distances
- zarch_extra_3_front_default_palette_dither_test3.png (15.7 KiB) Viewed 15849 times
Re: Hacker needed ... for Zarch ;-)
sirbod - I wanted to ask - since you are well acquainted with the source code - do you know under what conditions the sea monster shows up? I presume it's on certain waves in a random (but large enough) body of water. But I'd like to know the exact conditions if possible.
When I do see it - it always seems to be on Wave 2 in one of the larger areas of water. I've never seen it on Wave 1.
When I do see it - it always seems to be on Wave 2 in one of the larger areas of water. I've never seen it on Wave 1.
Re: Hacker needed ... for Zarch ;-)
I've not found the code that deals with it and it doesn't appear to be treated as an alien ship. My guess is its an object added when it builds the landscape map. If it always occurs on wave 2, then its not based on the seed used to generate the buildings and trees, so is either fixed or based on the landscape generation.RichP wrote:under what conditions the sea monster shows up?
Waves have a fixed ship list, fixed gravity, fixed fuel consumption rates and fixed landscape generation. The only randomness is in the buildings and trees, which are based off a seed.
Re: Hacker needed ... for Zarch ;-)
Thanks for the info
It's not always on Wave 2, but when I have seen it - it's usually on that wave. It could be because I spend longer over the water on that level than the first one though. The first level you just destroy everything over land mostly, if you are quick.
There was a letter in Acorn User/Micro User from someone who claimed you could always see it on Wave 2 if you flew in a certain direction upon starting the level. I can't remember the details now though. I'm sure I tried it on Arculator and it didn't work for me.
I do know you get a large points bonus for blowing up the monster - maybe 500 or even 1000 points. That might help locate the code,
I made a thread about the Sea monster here viewtopic.php?t=5815. According to that I have seen it on level 1. But I could have been mistaken when I wrote that.
Re-reading that thread, I just saw you are the guy who got to wave 40! Wave 6 is still my best.
It's not always on Wave 2, but when I have seen it - it's usually on that wave. It could be because I spend longer over the water on that level than the first one though. The first level you just destroy everything over land mostly, if you are quick.
There was a letter in Acorn User/Micro User from someone who claimed you could always see it on Wave 2 if you flew in a certain direction upon starting the level. I can't remember the details now though. I'm sure I tried it on Arculator and it didn't work for me.
I do know you get a large points bonus for blowing up the monster - maybe 500 or even 1000 points. That might help locate the code,
I made a thread about the Sea monster here viewtopic.php?t=5815. According to that I have seen it on level 1. But I could have been mistaken when I wrote that.
Re-reading that thread, I just saw you are the guy who got to wave 40! Wave 6 is still my best.
Re: Hacker needed ... for Zarch ;-)
If that's the case, it will be linked with the tree/building generation. Simple way to check this:RichP wrote:It's not always on Wave 2, but when I have seen it
- Load the game and immediately play to level 2, without demo mode kicking in
- Kill yourself and play to level 2
I think it appears if you load the game and leave demo mode to kick in, as I've seen it plenty of times while testing - I've not noted which level it was on though.

Re: Hacker needed ... for Zarch ;-)
That screenshot doesn't look like it has dithering enabled to me. Is it the right one?sirbod wrote:I've modified the dither colour calculation to prefer two colours that are close to each other, foreground dithering is now barely noticeable:
zarch_extra_3_front_default_palette_dither_test3.png
EDIT: Updated the image with the latest iteration. I've now updated Zarch's original triangle, quadrilateral and short line fill length routines to account for the X,Y position of the fill within the 50% dither.

Re: Hacker needed ... for Zarch ;-)
If you look over the top of the three rockets the furthest background is clearly dithered. If you load the image into a picture editor and zoom it you can see the foreground dithering too.tlsa wrote:That screenshot doesn't look like it has dithering enabled to me. Is it the right one?
Re: Hacker needed ... for Zarch ;-)
What is truly remarkable about this work is the way that you can watch the video showing the enhanced version and think it is how Zarch actually is. Then, when you watch the original version, it's like the same game but with the action going on under a table lamp. It's easy in this day and age to take the small (and not so small) things for granted until you are reminded of how things used to be.ctr wrote:If you look over the top of the three rockets the furthest background is clearly dithered. If you load the image into a picture editor and zoom it you can see the foreground dithering too.tlsa wrote:That screenshot doesn't look like it has dithering enabled to me. Is it the right one?
Re: Hacker needed ... for Zarch ;-)
Sure is, you can tell by looking at the colour of the ground in front of the landing pad. Without dithering, its yellow, with dithering its pale green.tlsa wrote:That screenshot doesn't look like it has dithering enabled to me. Is it the right one?
I recorded a video covering the dithering a few weeks ago, but didn't make it publicly available because the mic was popping. I've not had time to re-record it and am not about for a few weeks, so I've just made it available anyway.
Re: Hacker needed ... for Zarch ;-)
Glad you did !sirbod wrote:Sure is, you can tell by looking at the colour of the ground in front of the landing pad. Without dithering, its yellow, with dithering its pale green.tlsa wrote:That screenshot doesn't look like it has dithering enabled to me. Is it the right one?
I recorded a video covering the dithering a few weeks ago, but didn't make it publicly available because the mic was popping. I've not had time to re-record it and am not about for a few weeks, so I've just made it available anyway.
It's so exciting.
Bravo !
Re: Hacker needed ... for Zarch ;-)
Oh, wow! Yeah, the difference is very apparent in the video. Looks good!
Re: Hacker needed ... for Zarch ;-)
It does indeed look good.
I think you need some beta testers
I think you need some beta testers
Re: Hacker needed ... for Zarch ;-)
It must be time for an update!
Re: Hacker needed ... for Zarch ;-)
I've not touched it since the video about dithering. I've not had any spare time to devote to it.trixster wrote:It must be time for an update!
There has been one development though. Shortly after posting the videos on YouTube, I was anonymously sent the original source code. At some point I'll see if it compiles and compare it to the release version, if it's the same I'll probably drop everything I've done to date and migrate the changes to the original source. Hopefully this will also allow me to increase the framerate from 25fps.